一文说清Linux System Load

双十一压测过程中,常见的问题之一就是load 飙高,通常这个时候业务上都有受影响,比如服务rt飙高,比如机器无法登录,比如机器上执行命令hang住等等。本文就来说说,什么是load,load是怎么计算的,什么情况下load 会飙高,load飙高是不是必然业务受影响。
一 什么是load
我们平时所讲的load,其全称是Linux system load averages ,即linux系统负载平均值。注意两个关键词:一个是“负载”,它衡量的是task(linux 内核中用于描述一个进程或者线程)对系统的需求(CPU、内存、IO等等),第二个关键词是“平均”,它计算的是一段时间内的平均值,分别为 1、5 和 15 分钟值。system load average由内核负载计算并记录在/proc/loadavg 文件中, 用户态的工具(比如uptime,top等等)读的都是这个文件。
我们一般认为:
- 1、如果load接近0,意味着系统处于空闲状态;
- 2、如果 1min 平均值高于 5min 或 15min 平均值,则负载正在增加;
- 3、如果 1min 平均值低于 5min 或 15min 平均值,则负载正在减少;
- 4、如果它们高于系统 CPU 的数量,那么系统很可能遇到了性能问题(视情况而定)。
二 如何计算load
1 核心算法
坦白了不装了,核心算法其实就是指数加权移动平均法(Exponential Weighted Moving Average,EMWA),简单表示就是:
a1 = a0 * factor + a * (1 - factor),其中a0是上一时刻的值,a1是当前时刻的值,factor是一个系数,取值范围是[0,1],a是当前时刻的某个指标采样值。
为什么要采用指数移动加权平均法?我个人理解
- 指数移动加权平均法,是指各数值的加权系数随时间呈指数式递减,越靠近当前时刻的数值加权系数就越大,更能反映近期变化的趋势;
- 计算时不需要保存过去所有的数值,这对内核非常重要。
我们来看看,内核是怎么计算load average的,以下简称load。
上面的指数移动平均公式,a1 = a0 * e + a * (1 - e),具体到linux load的计算,a0是上一时刻的load,a1是当前时刻的load,e是一个常量系数,a 是当前时刻的active的进程/线程数量。
如上一节所述,linux 内核计算了三个load 值,分别是1分钟/5分钟/15分钟 load 。计算这三个load 值时,使用了三个不同的常量系数e,定义如下:
- #define EXP_1 1884 /* 1/exp(5sec/1min) */
- #define EXP_5 2014 /* 1/exp(5sec/5min) */
- #define EXP_15 2037 /* 1/exp(5sec/15min) */
这三个系数是怎么来的呢?公式如下:
- 1884 = 2048/(power(e,(5/(60*1)))) /* e = 2.71828 */
- 2014 = 2048/(power(e,(5/(60*5))))
- 2037 = 2048/(power(e,(5/(60*15))))
其中e=2.71828,其实就是自然常数e,也叫欧拉数(Euler number)。
那为什么是这么个公式呢?其中,5是指每五秒采样一次,60是指每分钟60秒,1、5、15则分别是1分钟、5分钟和15分钟。至于为什么是2048和自然常数e,这里涉及到定点计算以及其他一些数学知识,不是我们研究的重点,暂时不展开讨论。
我们看看内核中实际代码:
- /*
- * a1 = a0 * e + a * (1 - e)
- */
- static inline unsigned long
- calc_load(unsigned long load, unsigned long exp, unsigned long active)
- {
- unsigned long newload;
- // FIXED_1 = 2048
- newload = load * exp + active * (FIXED_1 - exp);
- if (active >= load)
- newload += FIXED_1-1;
- return newload / FIXED_1;
- }
就是一个很直观的实现。上面代码中,第一个参数就是上一时刻的load, 第二个参数就是常量系数,第三个参数是active的进程/线程数量(包括runnable 和 uninterruptible)。
2 计算流程
load的计算分为两个步骤:
1)、周期性地更新每个CPU上的rq里的active tasks,包括runnable状态和uninterruptible状态的task,累加到一个全局变量calc_load_tasks。
2)、周期性地计算 load,load的计算主要就是基于上述calc_load_tasks 变量。
第一个步骤,每个cpu都必须更新calc_load_tasks,但是第二个步骤只由一个cpu来完成,这个cpu叫tick_do_timer_cpu,由它执行do_timer() -> calc_global_load()计算系统负载。
整体流程如下图所示,在每个tick到来时(时钟中断),执行以下逻辑:
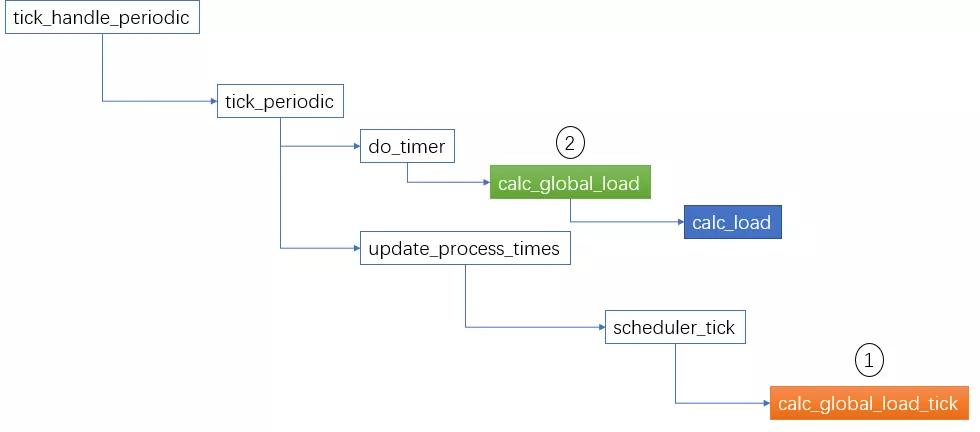
上图中,棕色的calc_global_load_tick函数就是完成第一个步骤的,绿色的calc_global_load 是完成第二个步骤,蓝色的calc_load 就是上一节中描述的核心算法。
这里需要说明的是,calc_global_load 把计算出来的load 值放在一个全局的变量avenrun中,它的定义是unsigned long avenrun[3],size 是3,用于存放1/5/15分钟的load。 当查看/proc/loadavg的时候,就是从这个avenrun数组中获取数据。
三 load高常见原因
从上述load的计算原理可以看出,导致load 飙高的原因,说简单也简单,无非就是runnable 或者 uninterruptible 的task 增多了。但是说复杂也复杂,因为导致task进入uninterruptible状态的路径非常多(粗略统计,可能有400-500条路径)。个人觉得,有些地方有点滥用这个状态了。
本人基于多年的linux 内核开发和疑难问题排查经验,总结了一些经验,以飨读者。
1 周期性飙高
曾经有些业务方遇到过load周期性飙高的现象,如果不是因为业务上确实有周期性的峰值,那么大概率是踩中了内核计算load时的bug。这个bug和内核的load采样频率( LOAD_FREQ)有关,具体细节不展开讨论。这个bug在ali2016,ali3000, ali4000中已经修复。
排除这个原因的话,可以接着查看是否磁盘IO的原因。
2 IO原因
磁盘性能瓶颈
iostat -dx 1 可以查看所有磁盘的IO 负载情况,当IOPS 或者 BW 高时,磁盘成为性能瓶颈,大量线程因为等待IO而处于uninterruptible 状态,导致load飙高。此时如果用vmstat 查看,可能会观察到 b 这一列的数值飙高, cpu iowait 飙高,/proc/stat文件中的procs_blocked 数值飙高。
云盘异常
云盘是虚拟盘,IO路径长而复杂,比较容易出问题。常见的异常是IO UTIL 100%,avgqu-sz 始终不为0,至少有1 。大家不要误解,io util 100%并不意味着磁盘很忙,而只意味着这个设备的请求队列里在每次采样时都发现有未完成的IO请求,所以当某种原因导致IO丢失的话,云盘就会出现UTIL 100%, 而ECS内核里的jbd2 线程,业务线程也会被D住,导致load 飙高。
JBD2 bug
JBD2是ext4 文件系统的日志系统,一旦jbd2 内核线程由于bug hang住,所有的磁盘IO请求都会被阻塞,大量线程进入uninterruptible状态,导致load 飙高。
排除IO原因之后,接着可以查看内存情况。
3 内存原因
内存回收
task 在申请内存的时候,可能会触发内存回收,如果触发的是直接内存回收,那对性能的伤害很大。当前task 会被阻塞直到内存回收完成,新的请求可能会导致task数量增加(比如HSF线程池扩容),load 就会飙高。 可以通过tsar --cpu --mem --load -i1 -l 查看,一般会观察到sys cpu 飙高,cache 突降等现象。
内存带宽竞争
大家可能只听说过IO带宽,网络带宽,很少注意内存带宽。其实内存除了在容量维度有瓶颈,在带宽层面也有瓶颈,只是这个指标普通的工具观察不了。我们开发的aprof 工具可以观察内存带宽竞争,在双十一保障期间在混部环境大显神威。
4 锁
通常是内核某些路径上的spin_lock会成为瓶颈,尤其是网络的收发包路径上。可以用perf top -g 查看到spin_lock的热点, 然后根据函数地址找到内核的源码。 伴随的现象可能有sys 飙高,softirq 飙高。
另外,采用mutex_lock进行并发控制的路径上,一旦有task 拿着lock 不释放,其他的task 就会以TASK_UNINTERRUPTIBLE的状态等待,也会引起load飙高。但是如果这把锁不在关键路径上,那么对业务可能就没啥影响。
5 user CPU
有些情况下load飙高是业务的正常表现,此时一般表现为user cpu 飙高,vmstat 看到 r 这一列升高,tsar --load -i1 -l 看到runq 升高,查看proc/pid/schedstats 可能会看到第二个数字也就是sched delay 会增加很快。
四 根因分析大招
1 RUNNABLE 型load飙高分析
如上所述,这种情况,通常是由于业务量的增加导致的,属于正常现象,但也有是业务代码bug导致的,比如长循环甚至死循环。但无论哪一种,一般都可以通过热点分析或者叫on cpu分析找到原因。on cpu分析的工具比较多,比如perf,比如阿里自研的ali-diagnose perf等等。
2 UNINTERRUPTIBLE型load飙高分析
所谓UNINTERRUPTIBLE,就是意味着在等,所以我们只要找到等在哪里,就基本找到原因了。
查找UNINTERRUPTIBLE状态进程
UNINTERRUPTIBLE,通常也称为D状态,下文就用D状态来描述。有一些简单的工具可以统计当前D状态进程的数量, 稍微复杂一点的工具可以把D状态进程的调用链也就是stack输出。这类工具一般都是从内核提供的proc 文件系统取数。
查看/proc/${pid}/stat 以及/proc/${pid}/task/${pid}/stat 文件,可以判断哪些task 处于D状态,如下所示:

第三个字段就是task的状态。然后再查看/proc/${pid}/stack 文件就可以知道task 等在哪里。如:

但有时候,D状态的task 不固定,这会导致抓不到D状态或者抓到stack的不准确。这时候,就得上另一个终极大招,延迟分析。
延迟分析
延迟分析需要深入内核内部,在内核路径上埋点取数。所以这类工具的本质是内核probe,包括systemtap,kprobe,ebpf等等。但是probe 技术必须结合知识和经验才能打造成一个实用的工具。阿里自研的ali-diagnose可以进行各种delay分析,irq_delay, sys_delay, sched_delay, io_delay, load-monitor。
五 总结
linux 内核是一个复杂的并发系统,各模块关系错综复杂。但是就load 而言,只要从runnable task和 uninterruptible task两个维度进行分析,总能找到根源。
页面地址:http://www.youmibao.com/n/445.html
在阿里云服务器怎么安装部署docker+Kubernetes(K8s)
目录前言Docker全面介绍Kubernetes(K8s) 全面介绍安装部署docker+Kubernetes(K8s)过程1.查阅K8S+docker的版本号对应关系2.将所需的安装包下载到本地(进行本地化安装)3.机器的准备(其中包括机器版本及配置)4.环...
云服务器阿里云DockerKubernetesK8s

centos 强制踢掉某登录用户的方法
linux是一个多用户操作系统,用户可以在不同的地方链接上LINUX服务器,在系统中我们可以用w或者who来查看用户[root@7273 ~]# whoroot pts/0 2018-05-5 20:45 (58.63.138.162)root pts/1 2...
CentOS用户踢掉
怎样使用Linux密钥登录云锁PC端
用户管理Linux服务器时,为了安全都会使用密钥进行登录,而不是使用root密码登录,但是云锁登录却需要使用root密码进行登录管理。遇到这种情况可以先设置root密码,再修改ssh禁止使用密码登录系统,这样既可以登录云锁,也解决了ssh登录安全的问题。Wdc...
linux服务器安全云锁密钥

5个安全运营中心优秀做法
研究数据表明,安全运营中心(SOC)可以显著推动企业的网络安全计划,这使SOC成为有效企业网络安全计划的基石。从平均总控制时间来看,非常成功的网络安全企业与不那么成功的网络安全企业相比,部署SOC的可能性高52%。实际上,仅部署SOC就可将企业控制数据泄露事故...
服务器安全网络安全SOC安全运营中心